Inferential Statistics
Inferential statistics are mathematical calculations performed to determine if the results from your sample of data are likely due to chance or are a true representation of the population. Inferential statistics are used to determine the probability of chance alone leading to your sampled results.
A few other key terms for inferential statistics:
The following factors contribute to determining if a statistical test is significant:
In most research settings, there are two very distinct types of hypotheses:
The statistical hypotheses are:
The type of inferential analysis you perform depends on your research question and the type of data collected. I think it is easiest to select the inferential analysis tool based on your graph!
- “Significant” = the results are very unlikely to have occurred due to chance.
- “Not significant” = the results could have to have occurred due to chance.
A few other key terms for inferential statistics:
- Significance level = the probability of saying a result is significant (not due to chance) when it actually was due to chance. A significance level of 0.05 (the standard used in biology) indicates a 5% risk of concluding that a result is significant when it was actually due to chance.
- p value = the probability value (p-value) is the probability of obtaining the sampling results due to chance.
- The smaller the p-value, the stronger the evidence that the results are significant (not due to chance).
- In biology, a p-value of less than 0.05 is considered significant. A p-value greater than 0.05 is considered non-significant.
- P values are expressed as decimals although it may be easier to understand what they are if you convert them to a percentage. For example, a p value of 0.0254 is 2.54%. This means there is a 2.54% chance your results could be random (i.e. happened by chance). Since 2.54% (0.0254) is less than 5.00% (0.05), we would say this result is “significant.”
The following factors contribute to determining if a statistical test is significant:
- How large is the difference between the means/medians of the groups? Other factors being equal, the greater the difference between central tendency, the greater the likelihood that a statistically significant difference exists. If the means/medians of groups are far apart, we can be fairly confident that there is a real difference between them.
- How much overlap is there between the groups? This is a function of the variation within the groups. Other factors being equal, the smaller the variances of the groups under consideration, the greater the likelihood that a statistically significant difference exists. We can be more confident that two groups differ when the scores within each group are close together.
- How many measures (trials or data points) are in the samples? The size of the sample (n) is extremely important in determining the significance. With increased sample size, measurements of the sample tend to become more stable representations of the population. If the result we find remains constant as we collect more and more data, we become more confident that we can trust the effect that we are finding.
- What significance level is being used to test the significance (how confident do you want to be about your conclusion)? A larger significance level requires less confidence in the conclusion. It is much harder to conclude a result is significant when you are only willing to have your results occur by chance 1 out of a 100 times (p < .01) as compared to 5 out of 100 times (p < .05).
In most research settings, there are two very distinct types of hypotheses:
- the research/experimental hypothesis - a statement of an expected or predicted relationship between two or more variables. It’s what the experimenter believes will happen in the research study. This hypothesis sets the stage to design a study to collect data to test its truth or falsity. In your IA, the research hypothesis is usually written at the end of your background information.
- the statistical hypotheses - the null and alternative hypothesis of inferential statistical tests. The statistical hypotheses are statements about whether a pattern/trend/difference is SIGNIFICANT (meaning, likely due to more than chance in sampling). The statistical hypotheses do not necessarily provide support for or against the research hypothesis that was tested. They just indicate whether chance alone likely could be the reason for the results.
The statistical hypotheses are:
- Null hypothesis (H0). The null hypothesis states that the results could be due to chance, that there is no significant relationship/difference compared to what could have resulted from random chance in sampling.
- Alternative Hypothesis (H1). The alternative hypothesis states that results are not likely due to chance, that there is a significant relationship/difference compared to what could have resulted from random chance in sampling.
The type of inferential analysis you perform depends on your research question and the type of data collected. I think it is easiest to select the inferential analysis tool based on your graph!
|
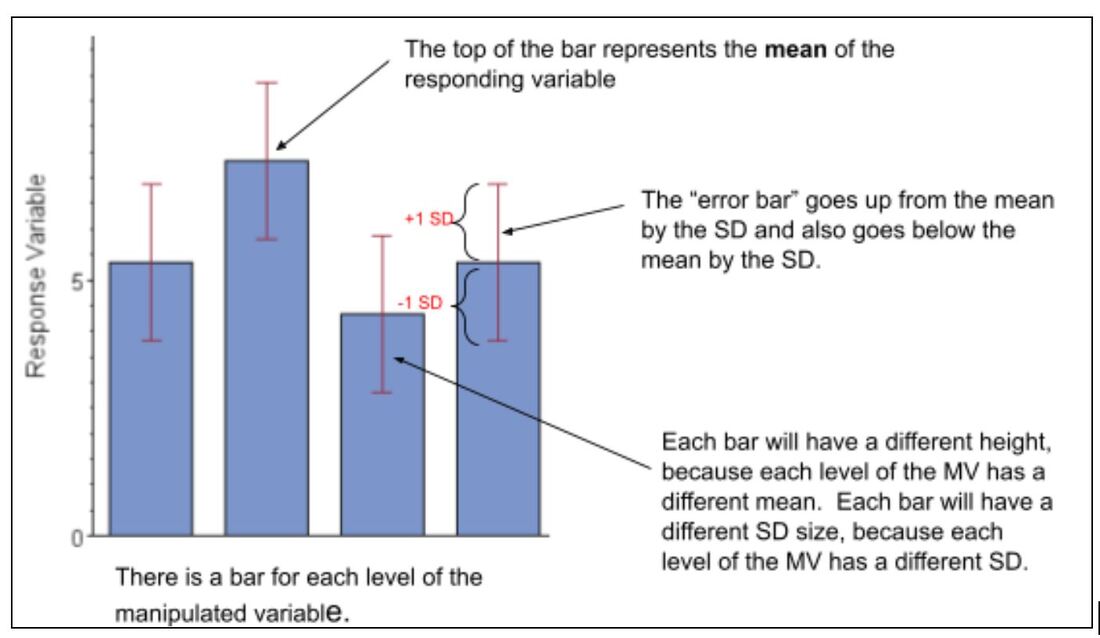
Bar chart:
Your data was not skewed (meaning it fit a normal distribution), so you graphed the MEAN with STANDARD DEVIATION using a bar chart. Your manipulated variable was qualitative. Both the T-test and ANOVA are used to determine if there is a significant difference between the means for the different levels of your manipulated variable. |
|
|
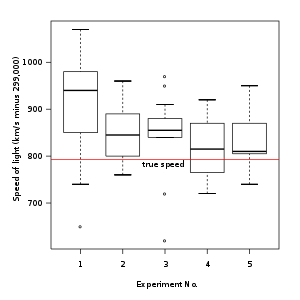
Box and Whisker:
You graphed the MEDIAN with QUARTILE bars using a box and whisker chart because your data was skewed (meaning it did not fit a normal distribution curve). Kruskal-Wallis is used to determine if there is a significant difference between the medians of the different levels of your manipulated variable. |
|
|
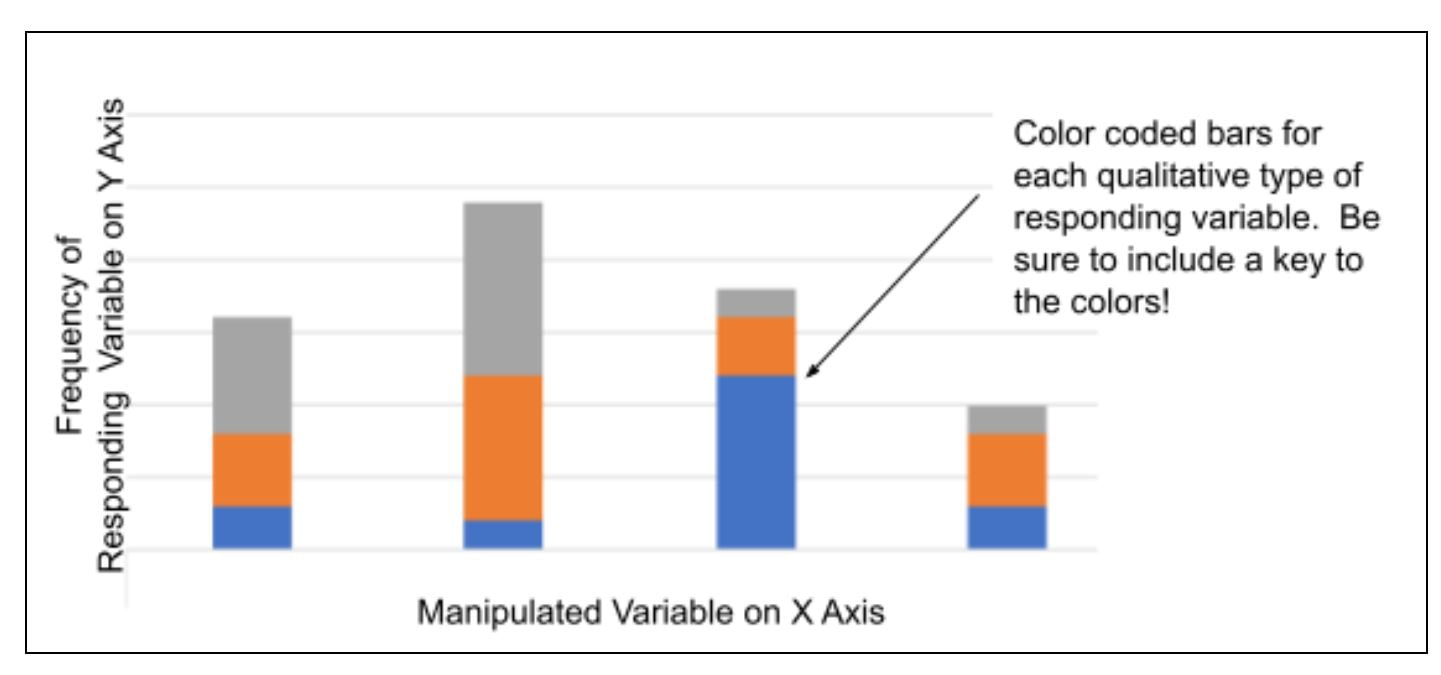
Stacked-bar Chart:
You created a stacked bar chart because you have levels of manipulation and a qualitative responding variable. The Chi-Square Goodness of Fit test of tells you if a difference exists between your observed counts and the counts you would expect if there were no relationship at all in the population. |
|
|
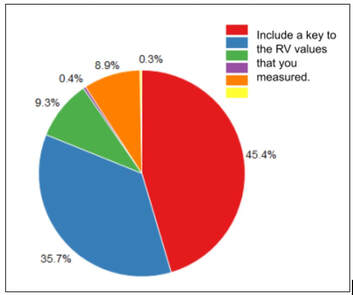
Pie Chart:
You created a pie chart because you do not have levels of manipulation and you had a qualitative responding variable. The Chi-Square Goodness of Fit test of tells you if a difference exists between your observed counts and the counts you would expect if there were no relationship at all in the population. |
|
|
Scatterplots and Line Graphs with a LINEAR relationship:
You created a scatter plot OR you graphed the mean with standard deviation bars using a line graph because your manipulated variable was quantitative. You added a LINEAR trendline. The Pearson’s Correlation (bottom of the page) is the test statistics that measures the statistical relationship, or association, between two continuous variables. |
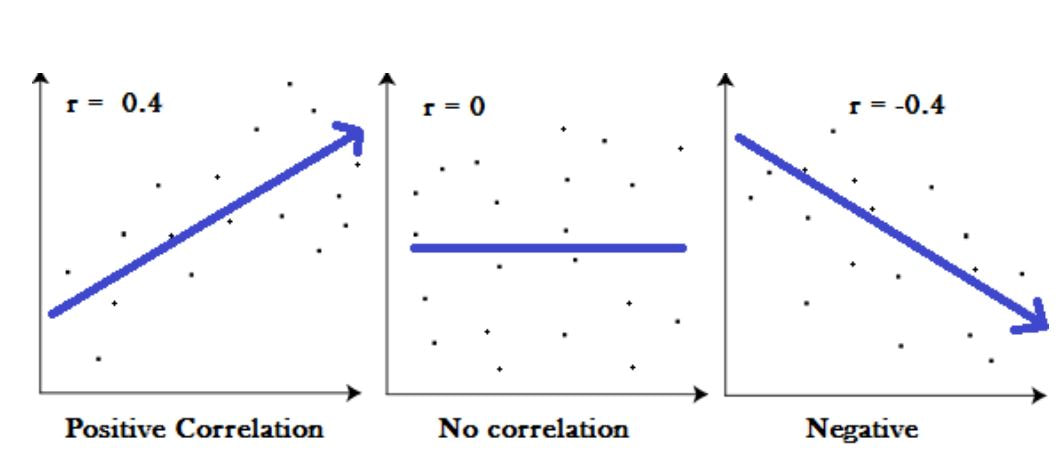
|
|
Scatterplots and Line Graphs with a NON-LINEAR but MONOTONIC relationship:
You created a scatter plot OR you graphed the mean with standard deviation bars using a line graph because your manipulated variable was quantitative. You added a NON-LINEAR trendline and the data is MONOTONIC (meaning, X and Y have a consistent relationship, positive, negative or inverse). Spearman's Rank Correlation is a measure of correlation for data that is non-linear. It assesses how well the relationship between two variables can be described using a monotonic function. |
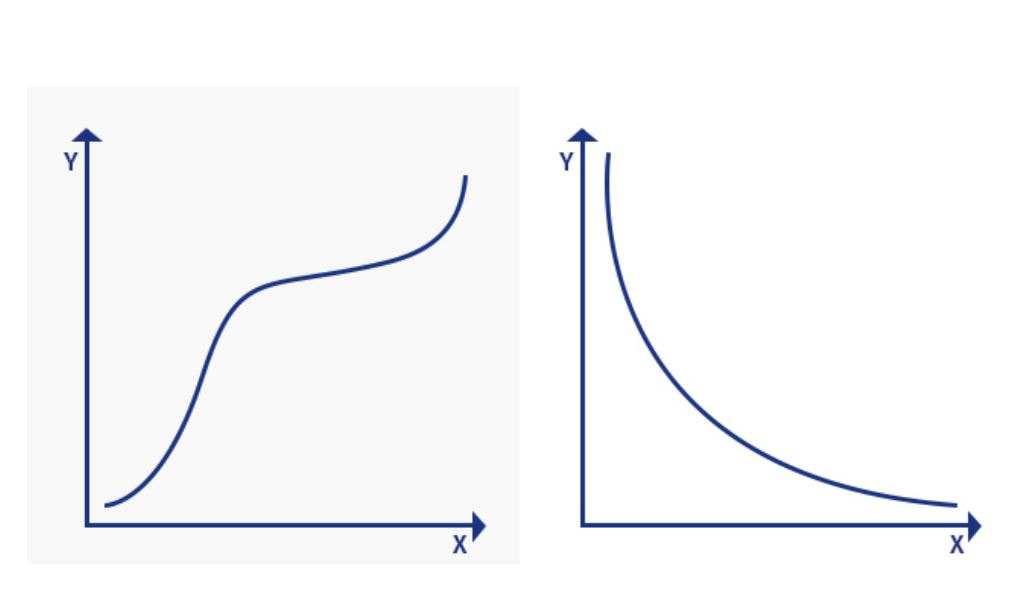
|
|
Scatterplots and Line Graphs with a NON-LINEAR and NON-MONOTONIC relationship
You created a scatter plot OR you graphed the mean with standard deviation bars using a line graph because your manipulated variable was quantitative. You added a NON-LINEAR trendline and the data is NON-MONOTONIC (meaning, sometimes Y increases and sometimes Y decreases with X). ANOVA is used to determine if there is a significant difference between different levels of your manipulated variable. |
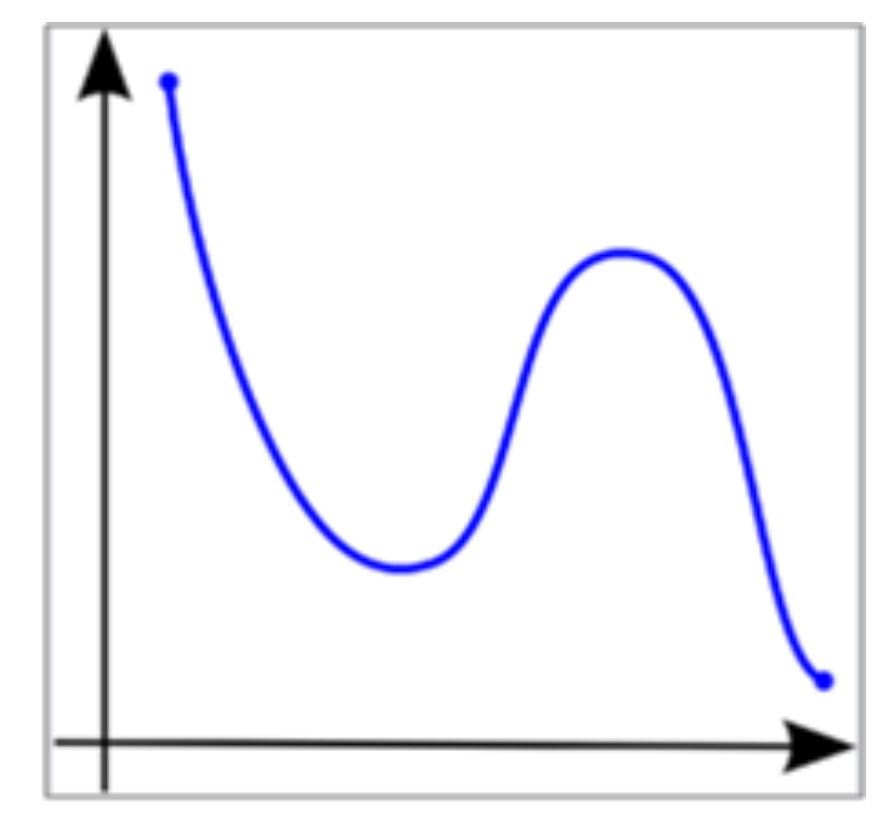
|